Galgame汉化中的逆向(二):系统字库与文字编码
Galgame汉化中的逆向(二):系统字库与文字编码
by devseed,
0x0 前言
上节我们谈了谈如何找到解密文本的函数,以及如何来反汇编分析。这节来谈谈有关汉化调用字库与编码的问题,如何解决乱码,以及windows上常用的相关函数。通常我们要做的是:
- 解除非日文系统区域限制
- 修正游戏由于编码问题无法找到对应文件
- 修正游戏中的乱码,标题中的乱码
- 修改游戏中字符的限制,为中文汉化做准备
0x1 文字编码
以winodws系统来看,字符编码主要有两种:
Multibyte(类型表示为 char *, LPSTR, ),WideChar(类型表示为 wchar_t *, LPWSTR, L"")。
Multibyte为变长字符,中ASCII字符为1字节,中文或日文等为两字节,不同系统编码不同,必须要指定对应的codepage才能正确显示。其中GB2312与shift-jis属于MultiByte;WideChar可以看作是unicode,或者说utf-16,两字节宽字符,所有系统编码都相同。
(1) utf-8
utf-8是一种Multibyte编码, 也是unicode的一种存储形式(可以理解为unicode是一种标准,utf-8是一种实现方式),最短为8位,通过位运算可以很容易和unicode进行变换。如下,将x位拼起来就是unicode,其中汉字通常为,0xEx开头。
1字节 0xxxxxxx
2字节 110xxxxx 10xxxxxx
3字节 1110xxxx 10xxxxxx 10xxxxxx
(2) shift-jis, SHJIS, cp932
shift-jis即 JIS X 0208子集的所有字符,可以参考sjis字符表。
第一位字节 使用0×81-0×9F、0xE0-0xEF (共47个)
第二位字节 使用0×40-0×7E、0×80-0xFC (共188个),没有7F。
一般查字库的时候多用这几个边界处字符定位,0x8141[、], 0x889f[亜], 0xe040[様]。
(3) gb2312, cp936
gb2312简中编码和sjis差不多,但是中间没有断层,这点要方便不少。
范围0xA1A1~0xFEFE,其中汉字编码范围是0xB0A1~0xF7FE, 详见gb2312字符表。
0x2 字符转换
不同编码集的字符转换通常要通过WideChar为桥梁,转换函数没MultiByteToWideChar、WideCharToMultiByte。通过CodePage来进行不同字符集到WideChar转换,其中932为sjis编码,936为gb2312编码。1
2
3
4
5
6
7int MultiByteToWideChar(
UINT CodePage,
DWORD dwFlags,
_In_NLS_string_(cbMultiByte)LPCCH lpMultiByteStr,
int cbMultiByte,
LPWSTR lpWideCharStr,
int cchWideChar);
有时候游戏调用CreateFileW等相关需要宽字符的函数,而MultiByteToWideChar中codepage为0(跟随系统),这时候就可能找不到文件,如下图。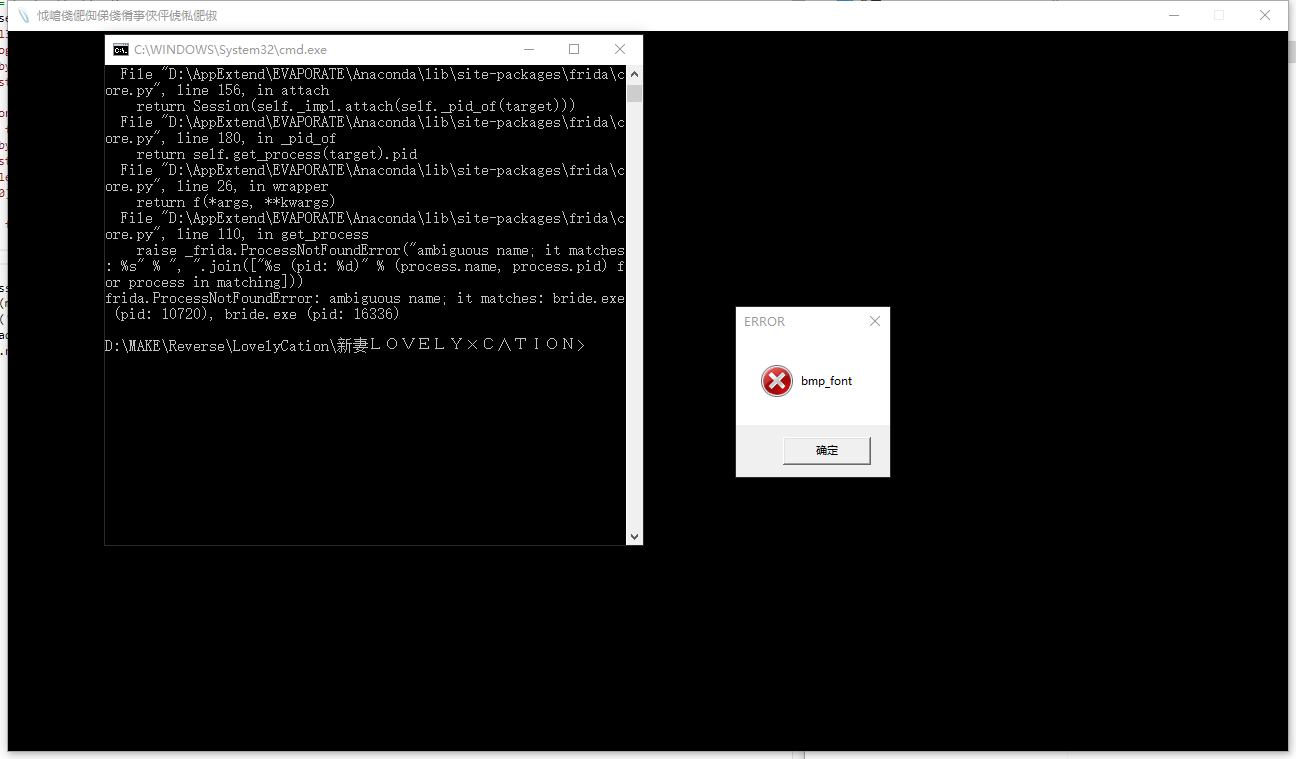
我们需要把代码改成0x3A4。可以通过hook此函数,hook不好用就直接改exe,如果利用push eax相关的短指令则需要用code cave了。
Frida hook MultiByteToWideChar1
2
3
4
5
6
7
8
9
10
11
12
13
14
15var kernel32_MultiByteToWideChar = Module.findExportByName("kernel32.dll", "MultiByteToWideChar");
console.log('MultiByteToWideChar at '+ kernel32_MultiByteToWideChar);
var g_multibyte_ptr;
var g_wide_ptr;
var g_n=0;
Interceptor.attach(kernel32_MultiByteToWideChar, {
onEnter: function (args, state) {
g_multibyte_ptr = args[2];
g_wide_ptr = args[4];
console.log(g_n +", cp"+args[0].toString(10))
args[0] = ptr('932');
g_n++;},
onLeave: function (retval) {
console.log(g_multibyte_ptr.readAnsiString() + ", " + g_wide_ptr.readUtf16String()) }
Code Cave
0x3 调用系统字库
游戏中通常用CreateFontIndirectA来选择字库,函数如下:
1 | HFONT CreateFontIndirectA( const LOGFONTA *lplf); |
日文游戏显示乱码原因多半是lfCharSet值输入为1(ANSI_CHARSET 0 BALTIC_CHARSET 1,跟随系统),语言根据徐通决定,我们要改成0x80 日语,汉化后要改成0x86 中文。其中lfCharSet大多在CreateFontIndirectA上面。
比如说改为,mov dword ptr ds:[532798], 80000000,修改乱码如图所示。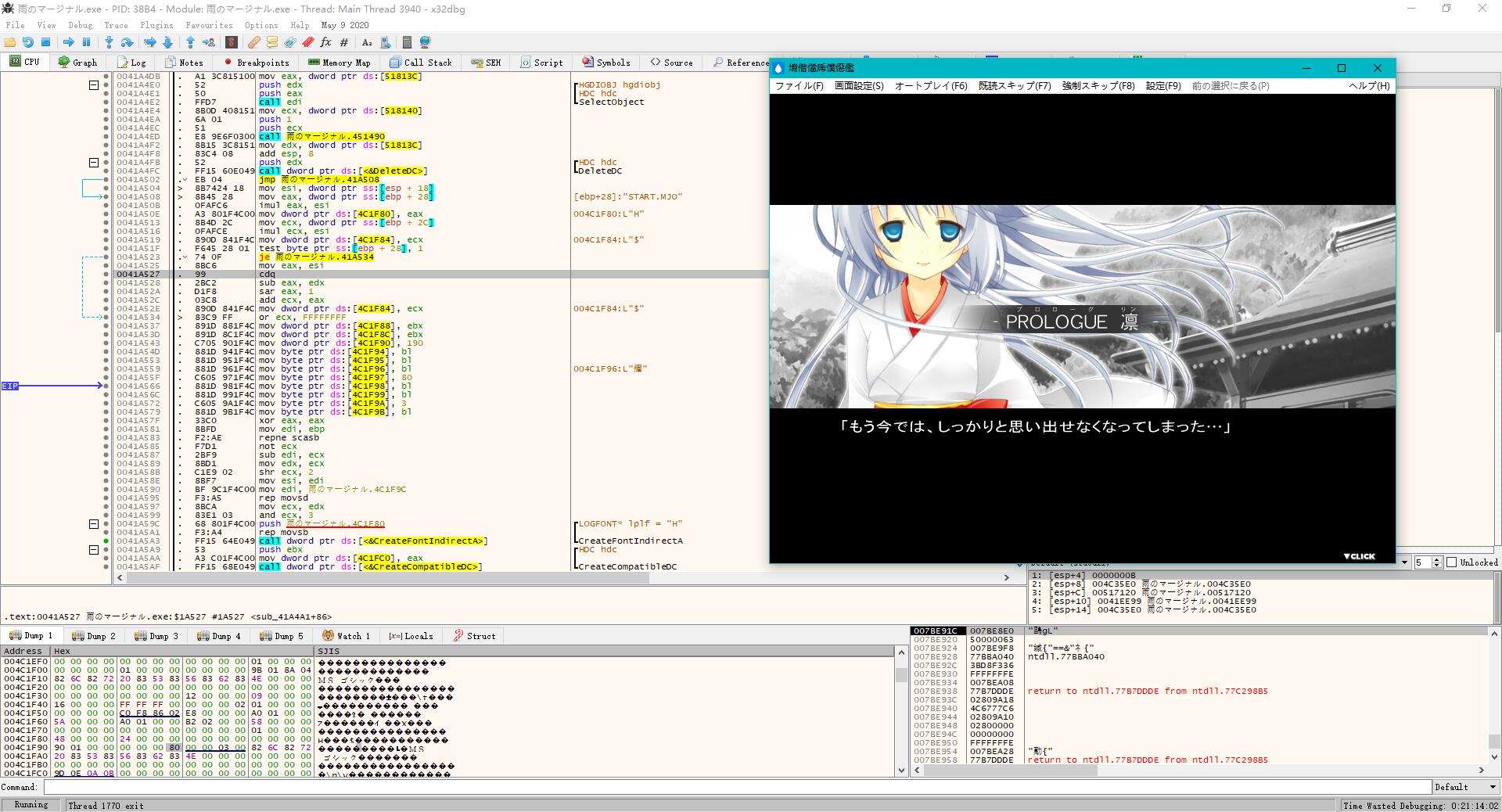
0x4 枚举系统字库
游戏中选择字体的时候通常用EnumFontFamiliesA或EnumFontFamiliesExA来枚举可用字库,通常会在FONTENUMPROCA回调函数中,通过charset来过滤其他字库。
如:
1 | mov edi, dword ptr ss:[ebp + 8] ;arg1 |
这个函数声明如下, charset就在LOGFONT结构体里, charset 0x80为日语, 0x86为中文。
1 | int CALLBACK EnumFontFamProc( |
0x5 其他
(1) 系统语言检测相关
一般来说常用的函数是GetSystemDefaultLCID,返回值是系统语言代码,英文 0x409,日文 0x411, 简中0x804,繁中0x404。
(2) 游戏窗口乱码修复
游戏窗口标题可能存储在游戏资源文件里,不一定在exe里面,通过CreateWindowEx来初始化窗口标题,或者SetWindowText。
(3) 点阵字模
GetGlyphOutlineA 将字符转换成点阵来输出,有些游戏的字体输出都是调用此函数,一般都会在调用这个函数之前进行字符边界校验。具体与上面类似,不再赘述。函数声明为:
1 | DWORD GetGlyphOutlineA( |








