Galgame汉化中的逆向(三):自定义字库分析
|Word count:1.8k|Reading time:6min|Post View:
Galgame汉化中的逆向(三):自定义字库分析
by devseed
0x0 前言
上节谈了一下一般pc游戏的文字编码与系统字库的调用,
但是主机游戏和部分pc游戏通常自带字库,这些字库有的是标准格式,而有的则是自定义格式。
自定义格式字库通常由两种类型:tile font, texture font。
此篇教程将以一种不同寻常格式的texture font为例,谈谈如何来分析自定义字库。

0x1 观察
此游戏字库很显然是font48.xtx,观看文件头xtx格式,后面的01是type。猜测再后面就是height,width,aligned height, aligned wight, offset相关的了(这里面有个坑人的地方是这游戏文件头是big endian,我看了好久才看出来)。
看到文件大小为900020h,结合数据猜测正文是0x20开始。
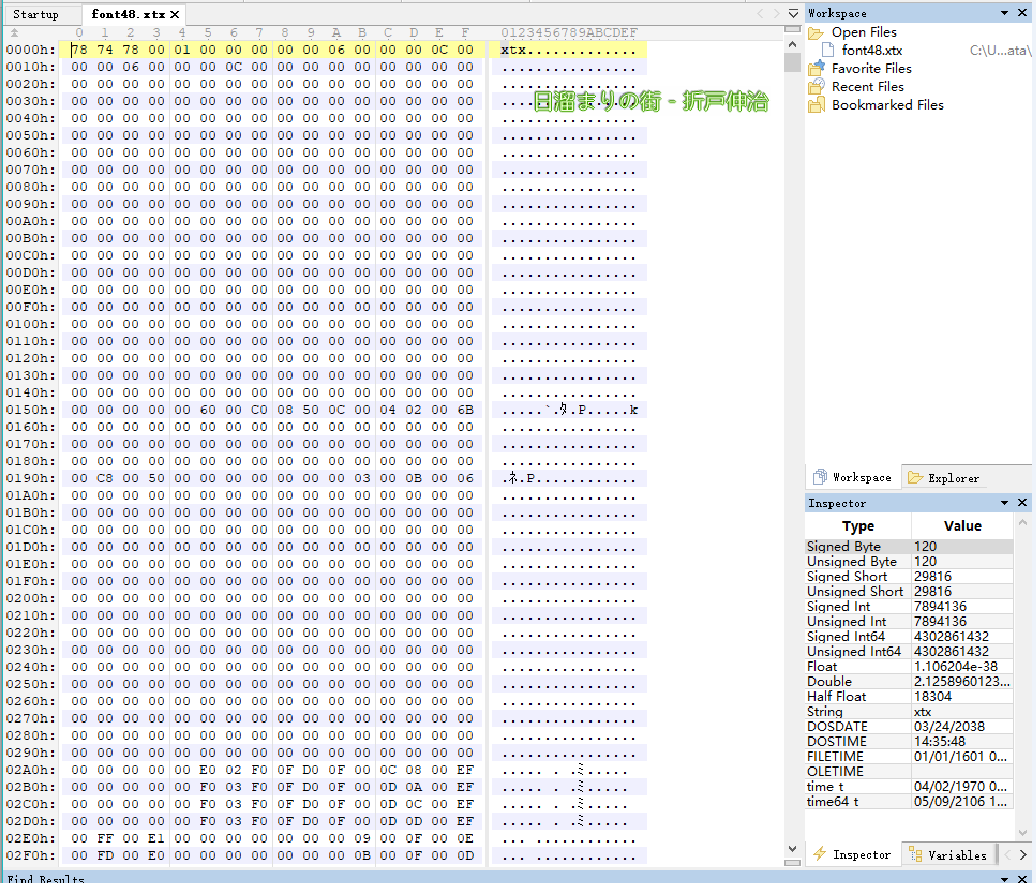
看着数据很规整,猜测没有压缩,但是查看纹理或者tile无论怎么看都很奇怪。
但是texture可以看出来大概几个数据块,所以很大可能是这个字库的数据流读取方式有问题,
我们需要找到这个字库读取顺序。

0x2 跟踪
游戏引擎将字库纹理以正确的字节流顺序载入,然后加载到显存里,由d9d9渲染到屏幕上。
可以从文本缓冲区入手,去跟踪d3d9了。
这部分说起来比较麻烦,因为是COM接口没有函数名称,非常需要耐心(对照d3d9.h来找)。
跟踪从d3d9.Direct3DCreate9开始,找到初始化ID3DXFont,然后再看调用栈找到字库读取函数。
由于arc_unpacker的大佬已经分析过了类似的字体,我们跳过跟踪这步,直接用大佬的结论来进行了。
0x3 字库分析
此font48.xtx字库编码为GRAY4,每个字符为48X48,共8192个字符。 block为48字节,每个block含4个坐标。
字库读取代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
| block_size = 48
intensity_map = (
0b00000000, 0b00010001, 0b00100010, 0b00110011,
0b01000100, 0b01010101, 0b01100110, 0b01110111,
0b10001000, 0b10011001, 0b10101010, 0b10111011,
0b11001100, 0b11011101, 0b11101110, 0b11111111)
def get_x(i, width, level):
v1 = (level >> 2) + (level >> 1 >> (level >> 2))
v2 = i << v1
v3 = (v2 & 0x3F) + ((v2 >> 2) & 0x1C0) + ((v2 >> 3) & 0x1FFFFE00)
return ((((level << 3) - 1) & ((v3 >> 1) ^ ((v3 ^ (v3 >> 1)) & 0xF))) >> v1)+ ((((((v2 >> 6) & 0xFF) + ((v3 >> (v1 + 5)) & 0xFE)) & 3)
+ (((v3 >> (v1 + 7)) % (((width + 31)) >> 5)) << 2)) << 3)
def get_y(i, width, level):
v1 = (level >> 2) + (level >> 1 >> (level >> 2))
v2 = i << v1
v3 = (v2 & 0x3F) + ((v2 >> 2) & 0x1C0) + ((v2 >> 3) & 0x1FFFFE00)
return ((v3 >> 4) & 1) + ((((v3 & ((level << 6) - 1) & -0x20)
+ ((((v2 & 0x3F)
+ ((v2 >> 2) & 0xC0)) & 0xF) << 1)) >> (v1 + 3)) & -2) + ((((v2 >> 10) & 2) + ((v3 >> (v1 + 6)) & 1)
+ (((v3 >> (v1 + 7)) // ((width + 31) >> 5)) << 2)) << 3)
def xtx_tex12gray(data, height, width, aligned_height, aligned_width):
gray = np.zeros([width*2, height*2], dtype=np.uint8)
print("%dX%d xtx, %d bytes-> %dX%d Gray"%(width, height, len(data), height*2, width*2 ))
for i in range(height*width):
abs_x = get_x(i, width, 2)
abs_y = get_y(i, width, 2)
if abs_y >= height or abs_x >= width:
continue
idx = i * 2
block_x = (abs_x // block_size) * block_size
block_y = (abs_y // block_size) * block_size
x = abs_x % block_size
y = abs_y % block_size
target_y = block_y + y
target_x1 = block_x * 4 + x;
target_x2 = block_x * 4 + x + block_size;
target_x3 = block_x * 4 + x + block_size * 2;
target_x4 = block_x * 4 + x + block_size * 3;
gray[target_y][target_x1] = intensity_map[data[idx] >> 4]
gray[target_y][target_x2] = intensity_map[data[idx] & 0xf]
gray[target_y][target_x3] = intensity_map[data[idx+1] >> 4]
gray[target_y][target_x4] = intensity_map[data[idx+1] & 0xf]
return gray
|
核心代码就是这么多,读取字库中的每一个字节,然后确定这个字节转换为图中的坐标(get_x(i, ), get_y(i,))。
但是光看估计很多人会对求坐标值的一堆位运算劝退,那么这些匪夷所思的位运算是在干什么?
这个时候静态很难看出来位运算在干什么,这时候我们就可以用打表法来看看到底字节流都到了图上的哪里去了。
打好表后规律一目了然,这也是这个字库最有意思的地方。
打表法打印字节流顺序与像素位置关系
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| def showtable():
width = 48
height = 96
lines = []
for i in range(height*2):
lines.append(width*2*[0])
for i in range(width * height):
x = get_x(i, width, 2)
y = get_y(i, width, 2)
lines[y][x] = str(i)
print(i, y ,x)
with open('position.csv', 'w', newline='') as fp:
f_csv = csv.writer(fp)
f_csv.writerows(lines)
|
用excel观看生产的表格,数字表示字库中的位置(i),用不同颜色隔开相邻chunk。
图中元素每4X8个像素构成一个小chunk,然后4X4个小chunk构成了一个大chunk。
这是一种分形结构,level=2为分两次,也就是我们所说的套娃。
(怪不的位运算那么一坨乱七八糟的,所以才说禁止套娃呀#滑稽)
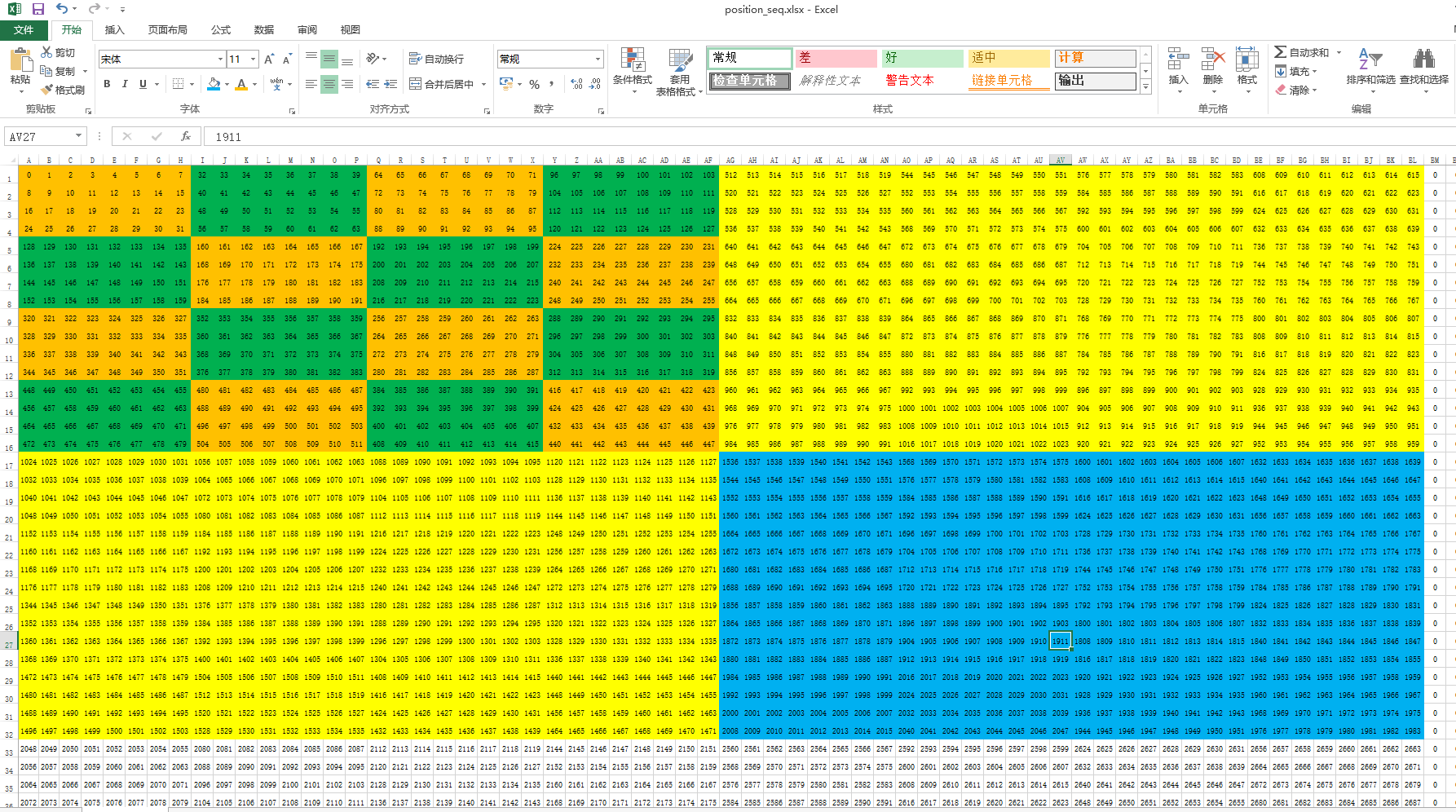
找到规律再检验一下,ok字库提取没问题。

0x4 重建字库
接下来的步骤就是重建字库了,重建分3 步:
(1) 建立简体字库的png图片,
(2) 修改fontmap或者将gb2312编码映射到sjis上,生成映射后的码表(.tbl)
(3) 将png转换为该游戏字库格式
现在来详细分析一下针对此游戏的方法:
(1)建立图片这个方法太多了,要求是每个字大小48X48,图大小6144X3072。
最简单的方法是用PIL的ImageFont打印,其中大小px要转换为pt。
(2)此游戏的fontmap我没找到,严重怀疑游戏是通过计算来得到的图中位置。
sjis编码的范围是程序里写死的,要改动涉及到的地方太多太麻烦。
本游戏的字库基本上是完整的sjis字库,从0x8140开始每个sjis字符包括不可打印字符都有(除了末尾的部分字符),
因此直接把gb2312按顺序映射到sjis编码即可,新建字符顺序是sjis但字符是简体字。
(3) 这部解包和封包差不多,只要把src和dst方向对调就行(当然宽高大小之类的参数要微调一下)
由于封包和解包算法非常相似,这里不再赘述,完整的程序可以参考我的github。
https://github.com/YuriSizuku/GalgameReverse/blob/master/criware/xtx_font.py
0x5 后记
本文分析了一个比较奇怪的套娃字库,简单的演示了一下一般游戏涉及到自定义字库如何处理,
虽然祝姫这个游戏不会汉化(文本量超大,原来汉化组解散,没有汉化组想做),
但是我发现这游戏很多地方还是有点意思,非常适合做教程素材,就整理了一下折腾过程发出来了。
Galgame汉化本身也是一种有意思的逆向,但是相对来说讨论的不多,
我费了好大劲才写完这个帖子,希望能抛砖引玉给大家一些启发吧。
非常感谢github上的各位大神把工具都开源,这些都是很好的学习材料。








